Punto 1: Optimización Numérica
1. Introducción
En esta etapa del proyecto, evaluamos el desempeño de nuestros algoritmos frente a dos de los retos más comunes en la optimización: las superficies planas y los múltiples mínimos locales. El objetivo no es solo encontrar el valor cero, sino observar cómo cada método navega por terrenos con dificultades geográficas distintas.
Para este análisis, seleccionamos dos funciones de prueba estándar que nos permiten comparar la eficiencia del Descenso por Gradiente frente a la capacidad de exploración de los algoritmos bio-inspirados. Evaluaremos si la precisión del cálculo tradicional es suficiente para superar obstáculos donde otros métodos suelen ser más robustos.
2. Justificación de Funciones Seleccionadas
No todas las funciones presentan los mismos retos de optimización. Para este experimento, seleccionamos dos paisajes matemáticos que permiten observar cómo reacciona cada algoritmo ante dificultades específicas:
2.1. Función de Rosenbrock: El reto de la convergencia lenta
También conocida como el “Valle de Rosenbrock”, elegimos esta función para evaluar si un algoritmo es capaz de seguir un camino estrecho y curvo. En este escenario, encontrar el valle general es relativamente sencillo, pero alcanzar el punto exacto más bajo representa un desafío monumental para muchos métodos debido a la extrema planicie de su fondo.
- Descripción: Presenta la forma de un valle estrecho, parabólico y muy plano. La dificultad radica en que la dirección de búsqueda cambia constantemente a lo largo de la curva.
- Fórmula Matemática: Para \(n\) dimensiones, se define como:
Ecuación 1: Función de Rosenbrock.
- Dominio de búsqueda: Evaluada típicamente en el intervalo \(x_i \in [-2.048, 2.048]\).
- Mínimo global (La Meta): El punto más bajo se encuentra en \(x = (1, 1, \dots, 1)\), donde el valor de la función es exactamente \(f(x) = 0\).

Figura 1: El valle curvo de Rosenbrock.
Tal como se ilustra en la Figura 1, la superficie muestra una curvatura pronunciada donde la mayoría de los algoritmos de optimización tienden a oscilar antes de converger.
2.2. Función de Rastrigin: El laberinto de la multimodalidad
Elegimos la función de Rastrigin porque es el ejemplo perfecto de una función multimodal. Su superficie está saturada de “trampas” o mínimos locales. Mientras que un algoritmo simple se quedará atascado en el primer hoyo que encuentre creyendo que ha ganado, un algoritmo robusto deberá ser capaz de “saltar” esos obstáculos para localizar el verdadero fondo.
- Descripción: Se basa en una parábola simple a la que se le añade una función coseno, creando una superficie altamente irregular llena de picos y valles profundos.
- Fórmula Matemática: Para \(n\) dimensiones, se define como:
Ecuación 2: Función de Rastrigin.
- Dominio de búsqueda: Evaluada en el cubo hiperdimensional \(x_i \in [-5.12, 5.12]\).
- Mínimo global (La Meta): El punto de éxito absoluto está en el centro exacto, \(x = (0, 0, \dots, 0)\), con un valor de \(f(x) = 0\).

Figura 2: El campo minado de Rastrigin.
La Figura 2 muestra que la función de Rastrigin es particularmente difícil para los métodos basados en gradiente porque el número de mínimos locales aumenta exponencialmente con el número de dimensiones.
3. Metodología del Experimento
Para garantizar una comparativa justa y rigurosa, establecimos un marco de evaluación estandarizado:
- Dimensiones: Pruebas en \(\mathbb{R}^2\) (para facilitar la interpretación visual) y \(\mathbb{R}^3\) (para evaluar la escalabilidad del algoritmo).
- Punto de Partida: Inicialización aleatoria dentro de los dominios estándar de cada función para evitar sesgos de proximidad.
- Competidores:
- Descenso de Gradiente (GD): El estándar de oro determinista basado en derivadas.
- Metaheurísticas Estocásticas: Evolución Diferencial (DE), Cúmulo de Partículas (PSO) y Algoritmo Evolutivo (EA).
4. Comportamiento en 2D
En nuestras pruebas para el caso de Rosenbrock, el Descenso por Gradiente requirió el máximo de iteraciones permitidas (10,000) y aun así no logró el cero absoluto, quedándose en un valor de \(f(x) = 0.000066\). Esto confirma la teoría del Hessiano mal condicionado: el algoritmo se ‘arrastra’ por el fondo del valle. Por el contrario, Evolución Diferencial (DE) alcanzó la meta exacta (\(f(x) = 0.000000\)) en apenas 123 generaciones, demostrando que su mecanismo de mutación vectorial es inmune a la planicie del valle.
En el caso de Rastrigin, el Descenso de Gradiente falló drásticamente al quedar atrapado en un mínimo local con un valor de 40.79, muy lejos del 0 esperado. Esto ocurrió porque, al iniciar en el punto [-3.52, -4.52], el gradiente lo succionó hacia el ‘hoyo’ más cercano sin capacidad de escape. En contraste, observamos un fenómeno fascinante con el Enjambre de Partículas (PSO): aunque el paisaje estaba lleno de trampas, la comunicación social del grupo permitió que la población convergiera al centro exacto (0,0) con un error de 0.000000 en solo 100 iteraciones.
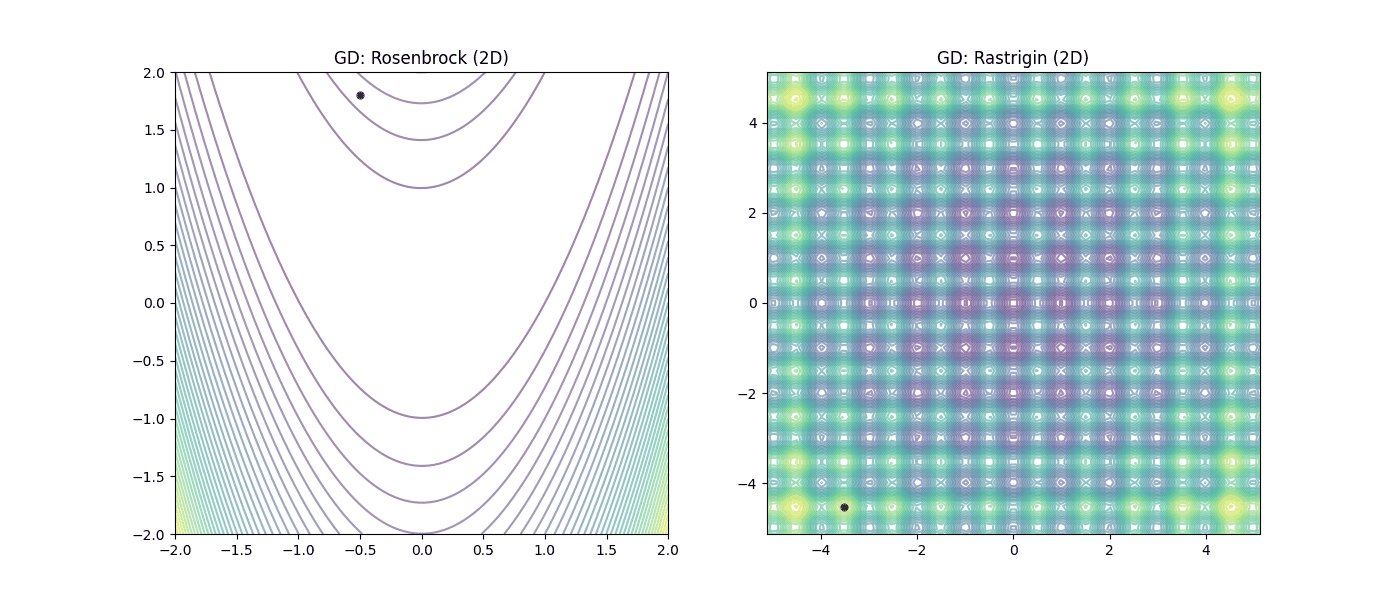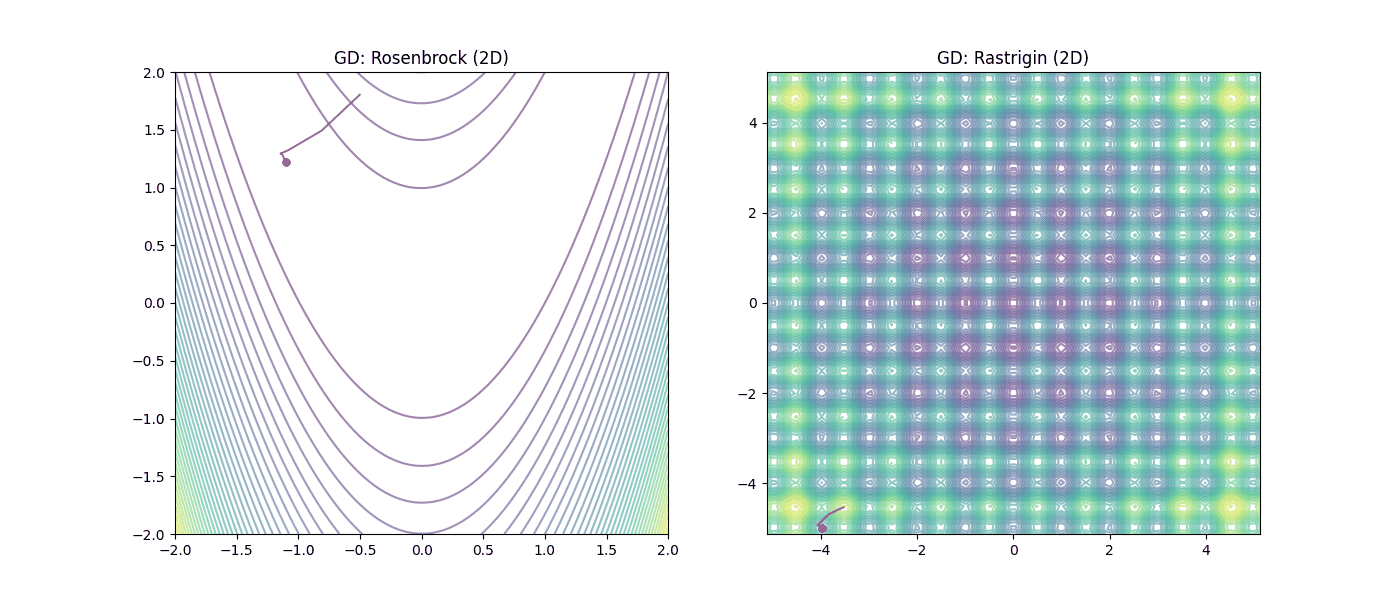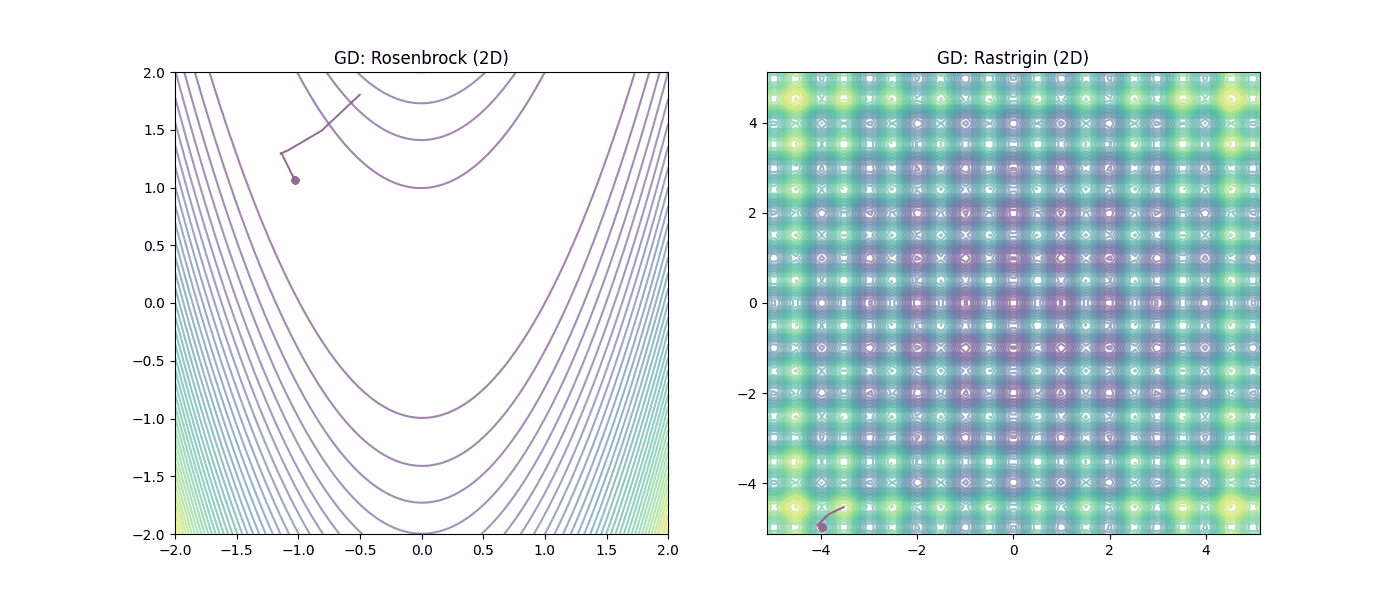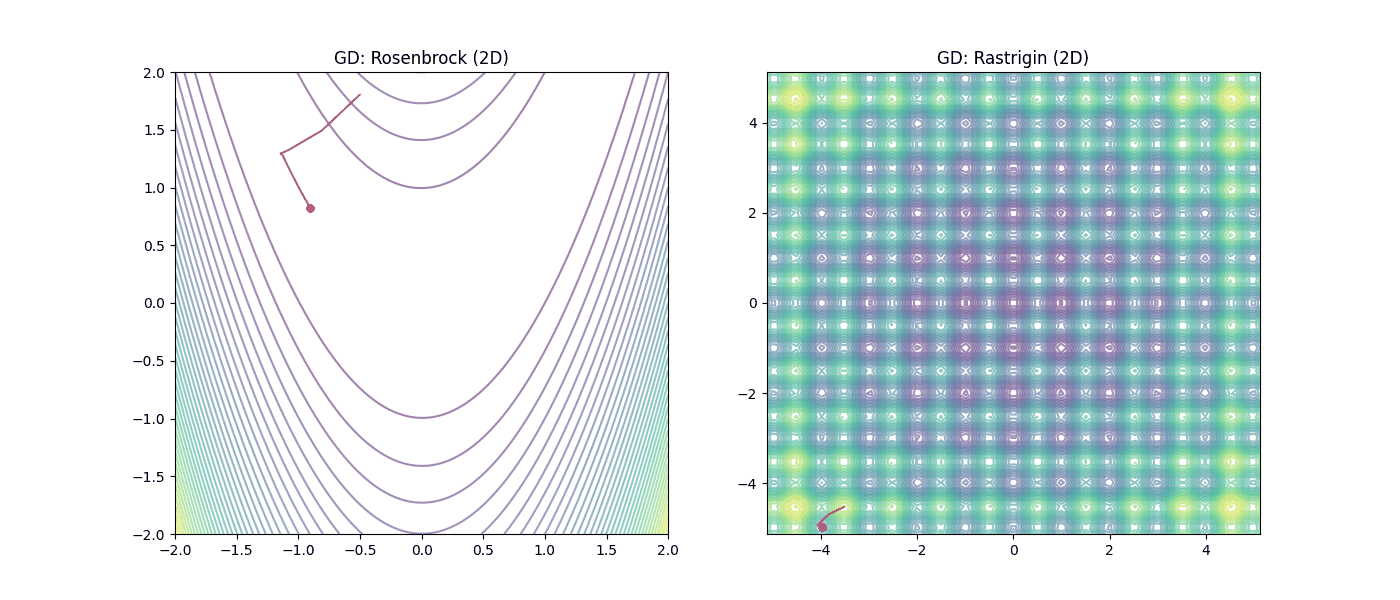
Figura 3: Desempeño del Descenso de Gradiente (GD). |
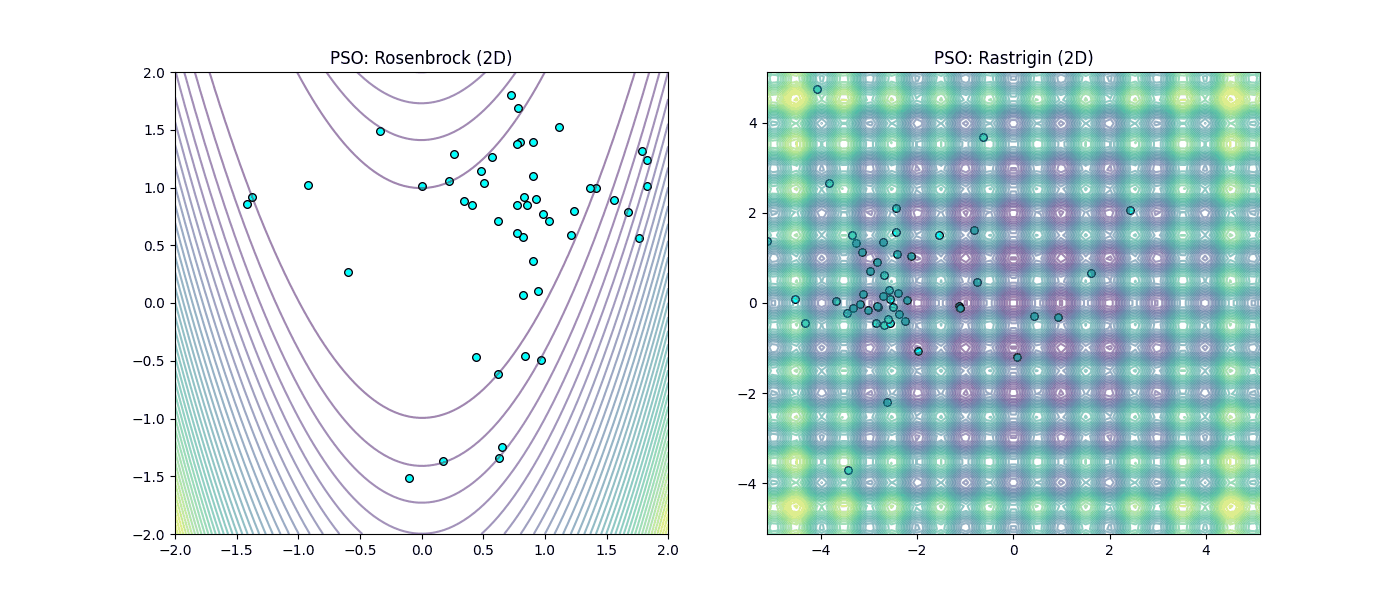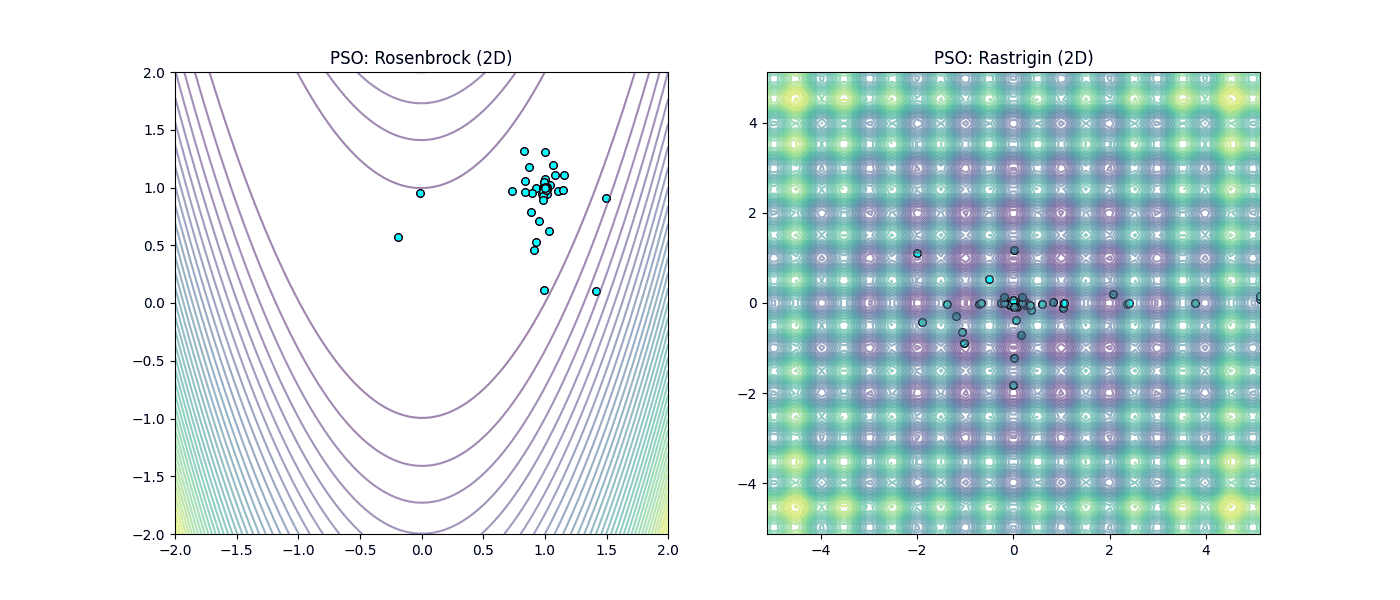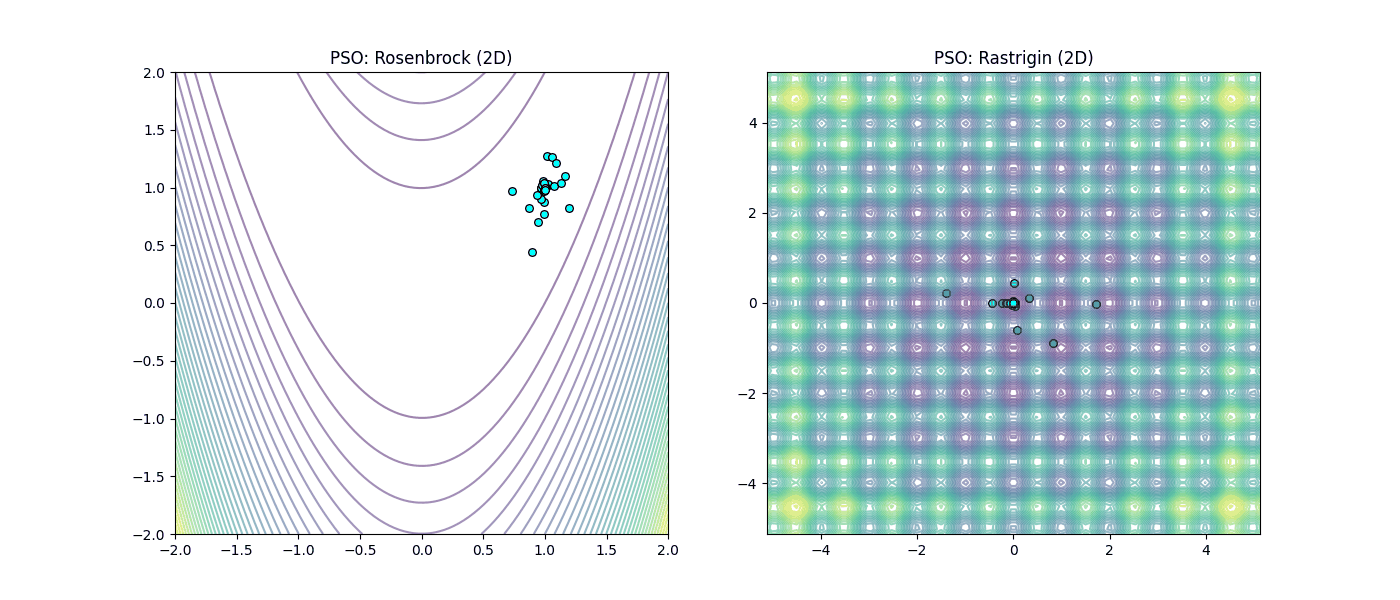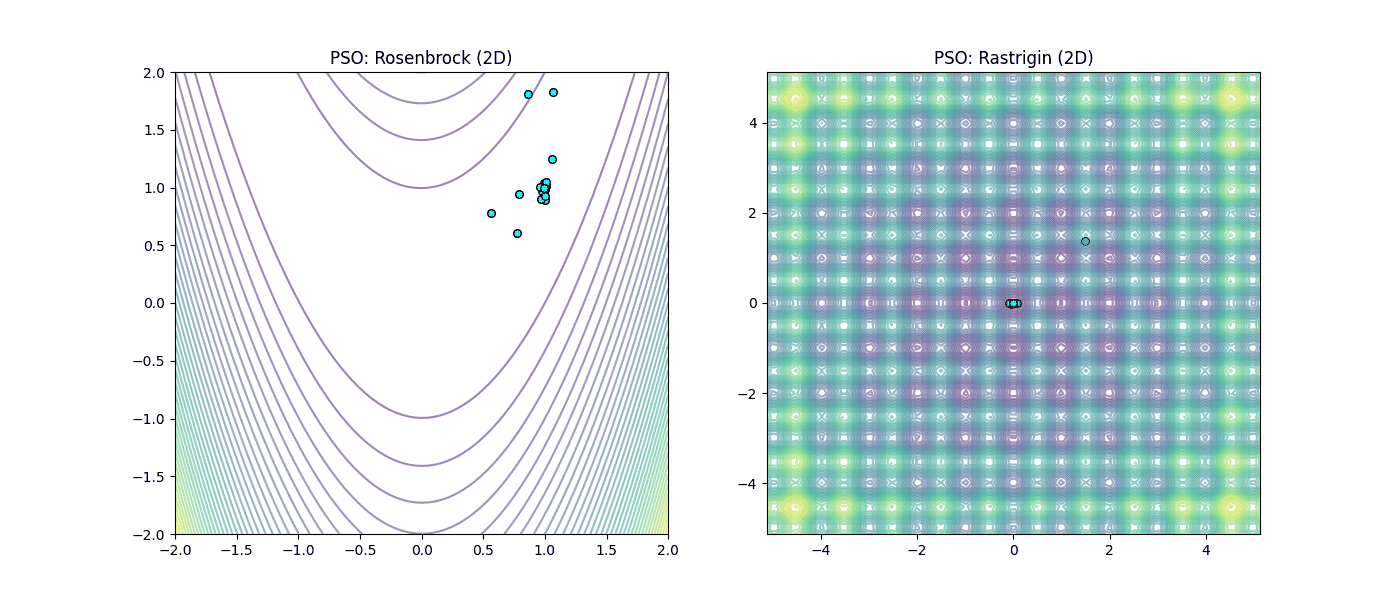
Figura 4: Desempeño de Cúmulo de Partículas (PSO). |
En la Figura 3 (GD), observamos cómo el método local sufre en el valle de Rosenbrock y queda atrapado irremediablemente en los mínimos locales de Rastrigin. Mientras que en la Figura 4 (PSO), se aprecia como el enfoque heurístico permite “saltar” las trampas de Rastrigin y mantener el avance en la llanura de Rosenbrock gracias a la inteligencia colectiva.
5. Comportamiento en 3D
Al escalar a 3D, la complejidad del mapa aumentó, pero las tendencias se mantuvieron. En Rosenbrock 3D, el Descenso por Gradiente agotó nuevamente sus 10,000 iteraciones, logrando un valor final de \(0.000008\). Si bien la precisión parece alta, el tiempo computacional fue excesivo para no haber llegado al mínimo global. La Evolución Diferencial (DE) volvió a mostrar su superioridad técnica, localizando el punto exacto (1,1,1) con un \(f(x) = 0.000000\), aunque requirió más esfuerzo que en 2D, subiendo a 257 generaciones debido al mayor volumen de búsqueda.
Para Rastrigin 3D, el Descenso de Gradiente volvió a demostrar su ‘miopía’ matemática: partiendo de [3.75, 1.03, 2.13], se estancó rápidamente en un valor de 20.89. El algoritmo simplemente no posee mecanismos para saltar fuera de los cráteres tridimensionales. Sin embargo, los algoritmos bio-inspirados no se vieron intimidados por la tercera dimensión: tanto el PSO como el DE lograron vencer la multimodalidad del terreno, alcanzando el fondo absoluto de la función (0.000000). Destaca especialmente el DE, que resolvió este laberinto en solo 108 generaciones, consolidándose como el método más robusto para problemas multivariables. La robustez superior de estos métodos se documenta visualmente en la Figura 5 y la Figura 6, donde se comparan las trayectorias de búsqueda en el espacio tridimensional.
Figura 5: Desempeño del Descenso de Gradiente (GD) en 3D. |
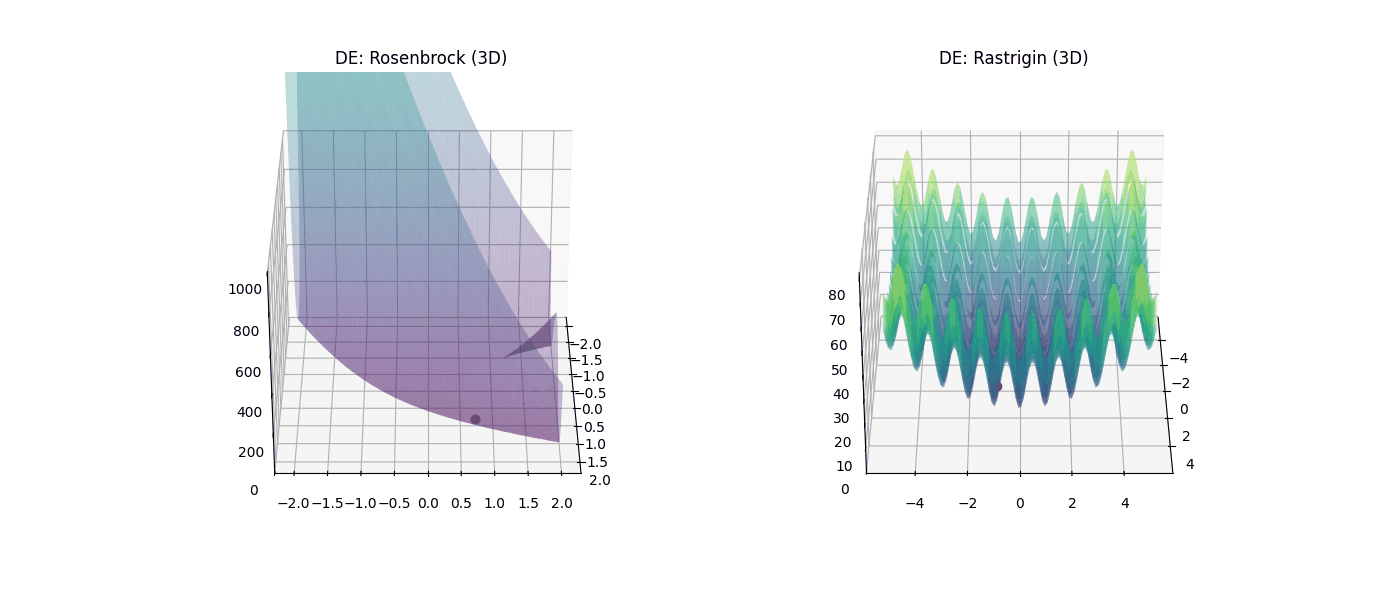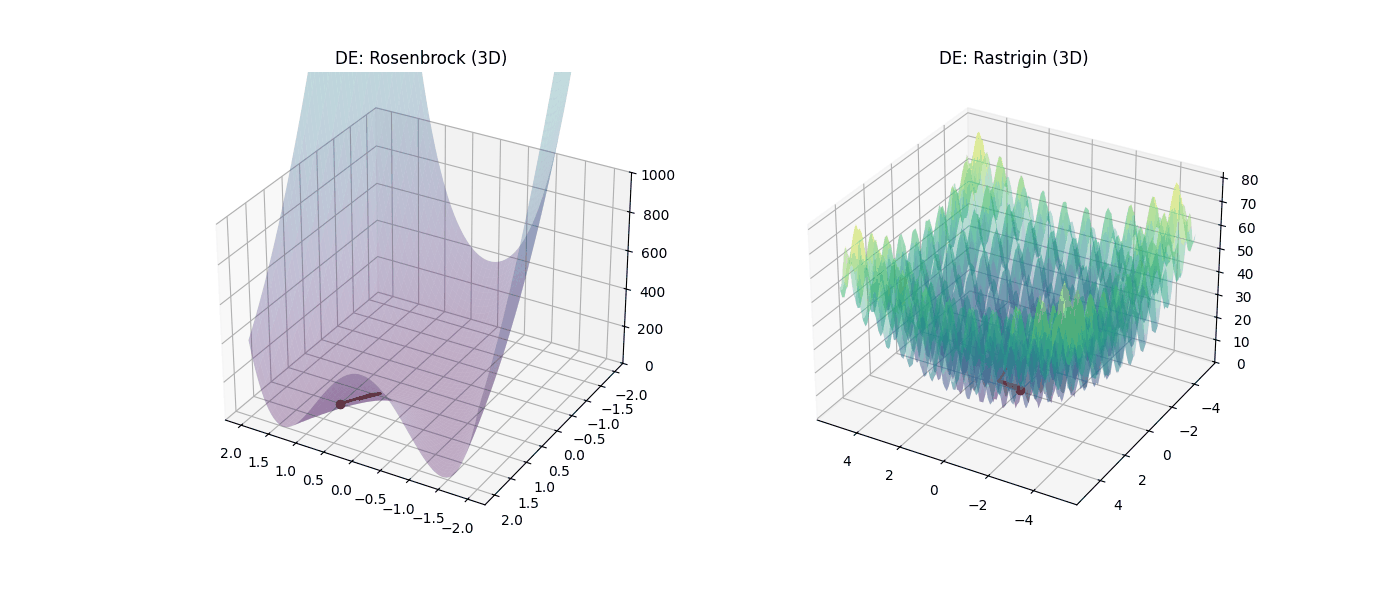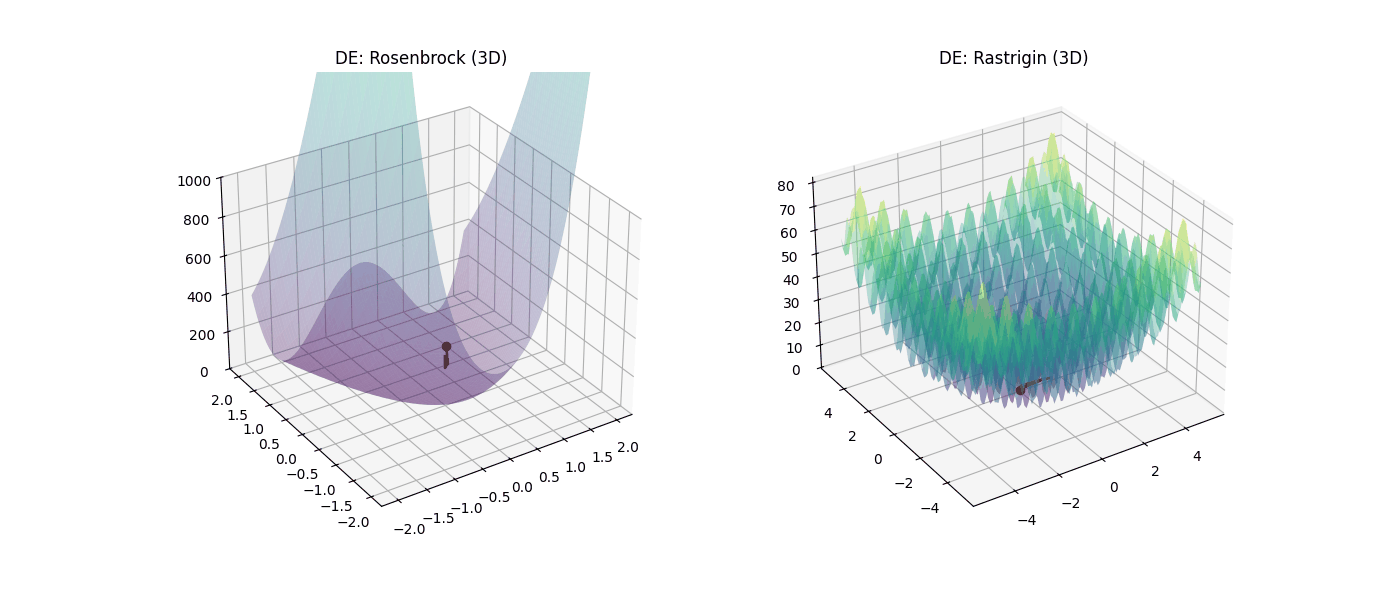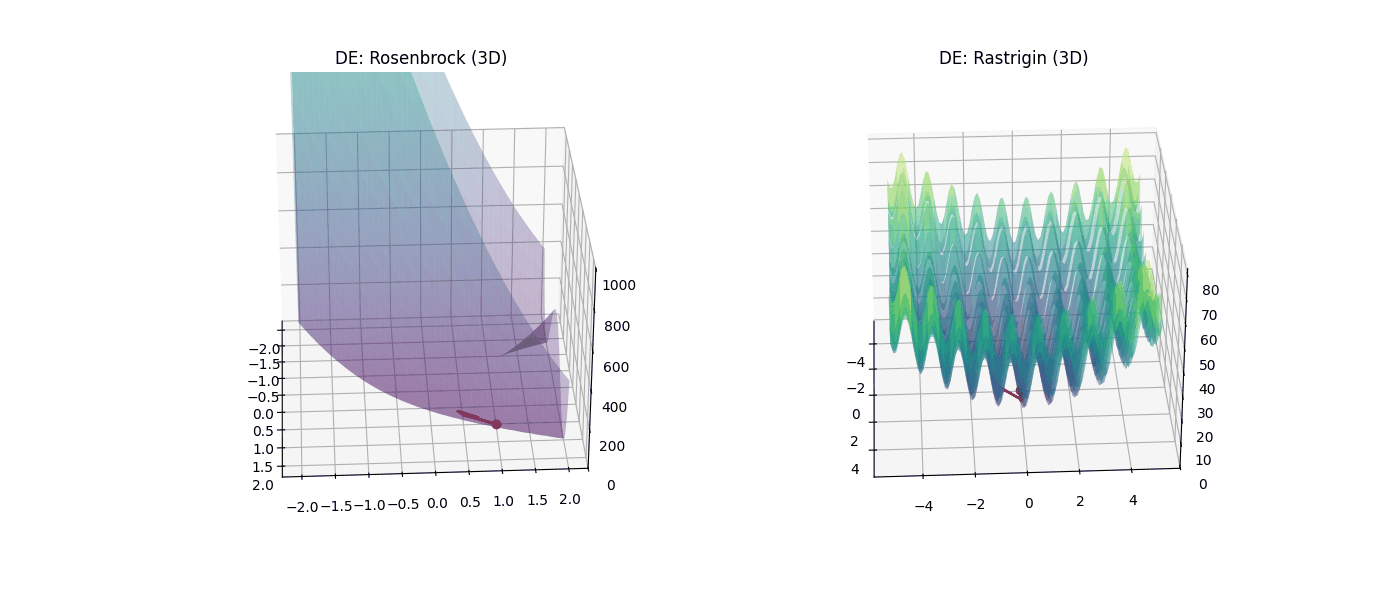
Figura 6: Desempeño de Evolución Diferencial (DE) en 3D. |
En la Figura 5, se observa como el algoritmo queda atrapado en los cráteres tridimensionales de Rastrigin y se arrastra ineficientemente por el valle de Rosenbrock agotando sus 10,000 iteraciones. Mientras que en la Figura 6, el DE muestra robustez superior al localizar el mínimo global exacto (0.000000) en ambos escenarios, consolidándose como el método más confiable para problemas multivariables.
6. Resultados cuantitativos
Los datos recopilados durante las pruebas experimentales se presentan de forma detallada en las siguientes tablas de resultados. En primer lugar, la Tabla 1 resume el desempeño sobre el valle de Rosenbrock.
Tabla 1: Resultados para la Función de Rosenbrock
Meta de la Función de Rosenbrock: Llegar al punto \((1, 1, \dots)\) con \(f(x) = 0\).
| Algoritmo | Dim | Punto de Inicio | Punto Final | f(x) Final | Iteraciones |
|---|---|---|---|---|---|
| GD (Gradiente) | 2D | [-0.502, 1.803] | [0.992, 0.984] | 0.000066 | 10,000 |
| GD (Gradiente) | 3D | [0.928, 0.395, -1.376] | [0.999, 0.997, 0.995] | 0.000008 | 10,000 |
| EA (Evolutivo) | 2D | [0.827, 0.916] | [1.010, 1.013] | 0.003832 | 100 |
| EA (Evolutivo) | 3D | [-0.482, 0.026, 0.251] | [0.631, 0.324, 0.120] | 1.157712 | 100 |
| PSO (Enjambre) | 2D | [0.827, 0.916] | [1.000, 1.000] | 0.000000 | 100 |
| PSO (Enjambre) | 3D | [-0.863, 1.132, 0.684] | [0.977, 0.955, 0.911] | 0.002642 | 100 |
| DE (Diferencial) | 2D | [0.805, 0.733] | [1.000, 1.000] | 0.000000 | 123 |
| DE (Diferencial) | 3D | [-0.020, 0.005, 0.094] | [1.000, 1.000, 1.000] | 0.000000 | 257 |
Posteriormente, la Tabla 2 muestra el comportamiento de los mismos algoritmos al enfrentarse a la multimodalidad extrema de Rastrigin.
Tabla 2: Resultados para la Función de Rastrigin
Meta de la Función de Rastrigin: Llegar al punto \((0, 0, \dots)\) con \(f(x) = 0\).
| Algoritmo | Dim | Punto de Inicio | Punto Final | f(x) Final | Iteraciones |
|---|---|---|---|---|---|
| GD (Gradiente) | 2D | [-3.523, -4.525] | [-3.980, -4.975] | 40.792967 | 354 |
| GD (Gradiente) | 3D | [3.750, 1.035, 2.131] | [3.980, 0.995, 1.990] | 20.894034 | 635 |
| EA (Evolutivo) | 2D | [1.107, 0.008] | [0.072, 0.021] | 1.099016 | 100 |
| EA (Evolutivo) | 3D | [1.013, 0.080, -0.229] | [1.026, 0.071, 1.979] | 6.172824 | 100 |
| PSO (Enjambre) | 2D | [-2.835, -0.077] | [0.000, 0.000] | 0.000000 | 100 |
| PSO (Enjambre) | 3D | [-3.047, -0.322, -0.011] | [0.000, 0.000, 0.000] | 0.000000 | 100 |
| DE (Diferencial) | 2D | [0.869, -0.895] | [0.000, 0.000] | 0.000000 | 57 |
| DE (Diferencial) | 3D | [-1.926, 1.044, 1.084] | [0.000, 0.000, 0.000] | 0.000000 | 108 |
De estas tablas, podemos extraer las siguientes conclusiones clave:
- Precisión: El Enjambre de Partículas (PSO) y la Evolución Diferencial (DE) fueron los únicos capaces de alcanzar el cero absoluto (\(0.000000\)) de forma consistente.
- Fracaso del Gradiente: El Descenso por Gradiente (GD) se estancó en mínimos locales muy altos en Rastrigin (\(f(x) \approx 40\) y \(20\)), confirmando que no sirve para funciones multimodales.
- Eficiencia de DE: La Evolución Diferencial (DE) en Rastrigin 2D solo necesitó 57 generaciones para hallar el centro, siendo el método más rápido y preciso en ese escenario.
- Convergencia de Rosenbrock: En el valle de Rosenbrock, el GD necesitó 10,000 iteraciones para apenas acercarse al mínimo, mientras que los métodos estocásticos llegaron mucho más rápido.
7. Discusión de Resultados
La comparación entre el Descenso por Gradiente (GD) y los Algoritmos Heurísticos (EA, PSO, DE) pone sobre la mesa un intercambio fundamental en computación: ¿Qué preferimos, rapidez o seguridad?
7.1. ¿Qué aportó el Descenso por Gradiente (GD)?
El mayor aporte del gradiente fue la economía de recursos, aunque con una limitación crítica en la visión global.
- El GD es “ligero”. En cada paso, solo evalúa la función una vez para decidir hacia dónde moverse. Por ejemplo, en Rastrigin 2D, el algoritmo solo necesitó 354 evaluaciones para dar por terminada su búsqueda.
- Si el terreno es sencillo, el gradiente es imbatible en velocidad. Sin embargo, su “miopía” matemática es evidente: en Rastrigin terminó con un valor de 40.79. Aportó una solución rápida, pero incorrecta, ya que se conformó con el primer pozo que encontró.
Es una herramienta de refinamiento. Útil solo si ya estamos muy cerca del objetivo o si la función no tiene trampas (es convexa).
7.2. ¿Qué aportaron los métodos heurísticos (EA, PSO, DE)?
El aporte de estos métodos fue la certeza del éxito, pagando el precio de un esfuerzo computacional mucho mayor.
A diferencia del gradiente, una sola iteración de un heurístico no equivale a una evaluación, sino a toda la población.
- Ejemplo: Si el PSO corre 100 iteraciones con 50 partículas, evaluó la función 5,000 veces.
- Si el DE necesitó 257 generaciones en Rosenbrock 3D, realizó 12,850 evaluaciones.
A cambio de ese esfuerzo masivo, el aporte es el cero absoluto. Lograron saltar cientos de mínimos locales en Rastrigin donde el gradiente se rindió. Aportaron la capacidad de explorar el mapa completo, asegurando que el resultado final sea el mínimo global y no un simple “hoyo” en el camino.
7.3. ¿Por qué son necesarias las múltiples corridas y el análisis estadístico?
Esta es la diferencia clave entre un algoritmo “ciego” y uno “explorador”:
- El Descenso por Gradiente es determinista; si sales del mismo punto, siempre llegarás al mismo error. No hace falta repetirlo.
- Los heurísticos usan el azar (estocasticidad) para saltar obstáculos. Al hacer varias corridas, confirmamos que el éxito del DE o del PSO (llegando a 0.000000) no fue un “golpe de suerte” en una ejecución aislada, sino una consecuencia de su diseño.
- Analizar el promedio de varias corridas nos permite decir con seguridad: “Este algoritmo es confiable el 100% de las veces”, algo vital cuando se optimizan procesos reales donde no conocemos de antemano dónde está el mínimo.
Para sintetizar las diferencias fundamentales entre ambos enfoques de optimización, presentamos a continuación la Tabla 3, que resume las métricas clave de desempeño.
Tabla 3: Síntesis Comparativa
| Métrica | Descenso por Gradiente (GD) | Métodos Heurísticos (DE, PSO, EA) |
|---|---|---|
| Valor Final (Precisión) | Pobre en funciones complejas (se estanca). | Excelente (encuentra el mínimo global). |
| Evaluaciones de Función | Muy pocas (Eficiente y rápido). | Muchas (Costoso computacionalmente). |
| Comportamiento | “Cae” en el mínimo más cercano. | “Salta” entre mínimos hasta hallar el mejor. |
| Aporte Principal | Rapidez para optimización local. | Robustez para optimización global. |
En conclusión, si el tiempo de cálculo es muy limitado y la función es simple, el Gradiente es suficiente. Pero si nos enfrentamos a un problema real, lleno de “trampas” y mínimos locales como Rastrigin, el gasto extra de evaluaciones de los Métodos Heurísticos (especialmente el DE y el PSO) es la única garantía de obtener una solución válida.
8. Referencias
SciPy v1.13.0. (s.f.). scipy.optimize.differential_evolution. SciPy Documentation. https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.differential_evolution.html
Soto, S. (2020). Particle Swarm Optimization [Repositorio de GitHub]. GitHub. https://github.com/sotostzam/particle-swarm-optimization
Wikipedia. (2024). Rastrigin function. https://en.wikipedia.org/wiki/Rastrigin_function
Wikipedia. (2024). Rosenbrock function. https://en.wikipedia.org/wiki/Rosenbrock_function